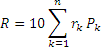Crime and the Hispanic Effect A hallmark of FBI and Bureau of Justice crime statistics is their failure to distinguish between Hispanic and non-Hispanic white criminals. Among criminologists this is known as the Hispanic effect. Addressing this issue at the annual convention of the Union of Nationalist Zapatistas, the featured speaker, Dr. Prodigy, introduces a technique for defeating the Hispanic effect. Herein is a transcript of Prodigy’s remarks. Madam President, honored guests, delegates to the national convention of the Union of Nationalist Zapatistas, ladies and gentlemen, I need scarcely tell you how proud I was to receive your invitation to present this evening’s lecture at the UNZ national convention. I can assure you that the memory of this occasion and of this great distinction you have conferred upon me shall never leave me. Tonight I shall cast such light as I can on the disaggregation of crime by race and ethnicity. I proceed guiltless of predisposition as though I were entirely disconnected from my personal experience. There is a need for such detachment, for the simple act of inquiry regarding such matters awakens dormant preconceptions not only in others but in me as well. The need for clarification arises because federal crime statistics mask the distinction between ethnic Hispanic and non-Hispanic white criminals. Tonight, I hope to bring this distinction into sharp focus. Two federal agencies are tasked with collecting and disseminating crime statistics. One, the FBI, is actually prohibited by law from collecting ethnic data. It classifies most Hispanic offenders as “white,” thus bloating the non-Hispanic white contribution to crime while completely missing the Hispanic contribution. The second agency, the Bureau of Justice Statistics, does no better. It classifies offenders only as “black,” “white” or “other race.” Again, most Hispanic offenders fall into the white category. Neither agency recognizes “Hispanic” as a classification. This blurring of ethnic differences by federal agencies has come to be known as the “Hispanic effect.” Tonight, I’ll introduce a method for overcoming the Hispanic effect, and demonstrate its use by disaggregating violent crime in America's largest cities. We begin by reaching across fields of human activity and arcs of time to a bit less than a century ago. While the eponymous forefather of the UNZ was engaged in a revolutionary struggle, men in other parts of the world were first learning how to determine the 3-D geometries of molecules. These investigators irradiated single crystals of pure compounds with monochromatic x-rays, and analyzed the patterns of radiation that exited the crystals. Such patterns, known as scattering or diffraction patterns, were uniquely related to the geometric arrangement of atoms in the crystals. Researchers worked backwards from the scattering patterns to find the arrangement of atoms that generated them. The technique, now improved by modern instrumentation and computational power, remains the gold standard for determining molecular structure. In their day, the early crystallographers captured scattered x-rays on photographic film. When developed, the film revealed the diffraction patterns as arrays of spots varying in optical density or darkness. The optical density of each spot, independent of other spots, carried information about the arrangement of atoms in the crystal. Optical densities were measured visually by comparing the spots to a calibrated film strip. The method was crude yielding densities good to plus or minus ten percent. Nevertheless, from these crude measurements, atomic coordinates were determined to within 10‑12 meters or a few hundredths of the distance separating neighboring atoms. Such precision was possible because the problem of locating the atoms in the crystal was vastly overdetermined. Hundreds, perhaps thousands, of spots were measured to find a few handfuls of atomic coordinates. We can learn from the early crystallographers. Under proper conditions, less than high-quality input can yield high-quality output. The trick is to have lots of linearly independent data that far outnumber the unknowns, the more data the better. This is a mathematical reality as true in sociology as in crystal structure analysis. It forms the basis of how we will defeat the Hispanic effect. Crimes have no race or ethnicity. Criminals do. Consequently the FBI, though prohibited from ascertaining ethnicity, is free to count crimes. In fact, it is obliged to do so. In 1930, in order to assess the nation’s criminality Congress enacted legislation requiring the FBI to determine the number of offenses known to law enforcement irrespective of whether or not arrests were made. Each year the agency solicits crime counts from every law enforcement jurisdiction in the nation. Its findings may be found in the annual publication Crime in the United States. Gathering accurate crime counts is not as simple as one might first think. The FBI relies on faithful reporting by local law enforcement agencies. But data from these sources are sometimes incomplete, incorrect or even missing. FBI-designed algorithms detect and correct most outliers. Nevertheless, the corrected crime counts suffer unavoidably from residual error originating at their source. On the plus side the data is easily available and there are tons of it. Attempts to defeat the Hispanic effect appear from time to time. Irrespective of their differences they have one thing in common; they all count criminals. We count crimes. When assessing the probability of being victimized the number of offenders does not enter into the calculation. The frequency of crime does. A mugger that accosts fifty victims a year and another that accosts five contribute equally to a count of criminals, yet represent very different threats to the street. Improbable as it may seem, an FBI tally of crimes without regard to race or ethnicity will enable us to separate the criminal behavior of Hispanics from that of non-Hispanic whites. I am reminded of how I came to ponder the defeat of the Hispanic effect. While strolling through Prospect Park one May morning inhaling the scents of spring it occurred to me that the threat of criminal violence from Hasidic Jews in Crown Heights was the same as it was in Borough Park. I hypothesized that this idea might extend beyond neighborhoods and Hasidim. It could, for example, include whole cities and other ethnic or racial groups. After some thought I formulated this proposition: In any given calendar year, the violent-crime rates of the racial and ethnic groups that inhabit a city are characteristic of the groups, but are independent of the particular city in which the groups reside. This is an empirically verifiable proposition; however, it needs to be developed first. Little could give me more gratification and delight than being privileged to carry out the development here at the UNZ convention. There are several common conventions for expressing crime rates. We define a city’s crime rate (in a given year) as the number of offenses committed per 1000 inhabitants. It is convenient to express a city’s crime rate as a sum of contributions from the various racial and ethnic groups that inhabit it. Then, for a city of n demographically distinct groups we can without assumption write its crime rate R as:
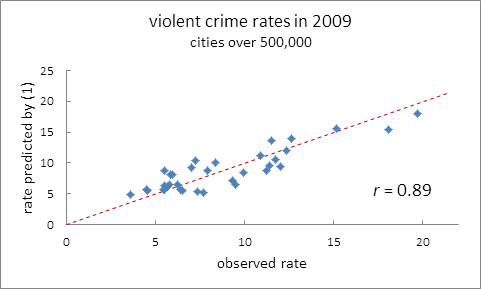
where rk is the per capita crime rate of group k, and Pk is the kth group’s population percentage. (UNZ delegates will immediately comprehend this relation, but you might consider giving it to your children as an exercise.) All the quantities in (1) except the group crime rates, rk, are available for every city in the US; the Census Bureau supplies population percentages and the FBI crime rates. If, as has been asserted, every racial and ethnic group has its own characteristic per capita violent crime rate independent of where the group is located, then (1) must be satisfied by the same set of r’s in every city. This is a verifiable corollary of our proposition that will serve to test it. Equation (1) applied to each of the n cities, forms a system of n equations in the group crime rates. Because there are many more cities than racial or ethnic groups, the group crime rates are overdetermined. So long as errors in Census Bureau and FBI data are not systematic, overdetermination reduces their effect. In 2009 and 2010, there were 35 US cities with populations exceeding 500,000. We modeled violent crime in these cities assuming all the crime was committed by members of the four dominant population groups: Hispanics, non-Hispanic blacks, non-Hispanic whites and Asians. That gave us four terms on the right-hand side of (1). Together the four groups accounted for 97% of the combined population of the cities. (Inclusion of minor groups added more noise than benefit.) Honolulu, with 21% of its inhabitants being Pacific Islander or mixed race, did not fit the model; accordingly, it was excluded from the analysis. The Census Bureau provided population percentages for each of the remaining cities, giving us a system of 34 equations in four group rates. Using the least squares criterion, group rates were adjusted to minimize the sum of squared differences between the FBI’s reported rates and those calculated by (1). The plot in Figure 1 compares the predicted rates with those observed in 2009.
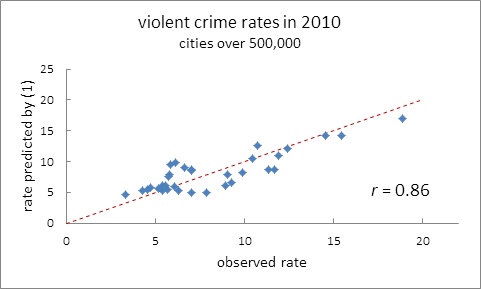
Each point plotted in Figure 1 corresponds to a specific city. The points are seen to cluster about a line of unit slope through the origin, that is, the line of perfect agreement. If the model were exact, the data free of error, and fluctuations in human behavior nonexistent, all the points would fall on that line. Given that none of these circumstances is totally met, the visibly narrow distribution of points about the line suggests that the model of group-characteristic violent crime rates explains most of the observed variation in big-city violent crime rates. Still, one would like a more quantitative assessment of the model’s applicability. I would ask the honored delegates to indulge me a moment to address a rather technical issue. The procedure just implemented is known to statisticians as regression through the origin. This simply means that we did not include a constant term on the right-hand side of (1). Our model demands its omission, for its inclusion would imply a non-zero crime rate in a hypothetical city with no inhabitants. The problem with regression through the origin is that the usual measures of goodness of fit do not apply. Much discussion in the literature concerning this issue has produced no unqualified resolution. Some statisticians suggest using the sample correlation between observed and predicted values to judge goodness of fit. By this criterion, the observed correlation of 0.89 supports our visual impression. The procedure, repeated with 2010 data, yields a correlation a bit lower at 0.86. Figure 2 shows the 2010 plot. Data for both years are included in an appendix.
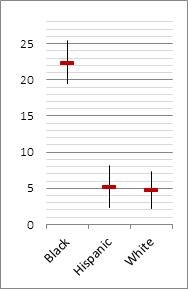
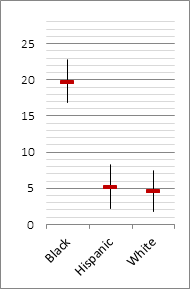
We turn now to the group contributions themselves. Tables 1 and 2 present the big-city characteristic violent crime rates for blacks, Hispanics and non-Hispanic whites in 2009 and 2010, respectively. Included in the tables are standard errors, p-values and 95% confidence intervals. The rates obtained for Asians in both years were not statistically significant (p = 0.4 and 0.5, respectively). Small Asian populations (less than 5% in most of the cities sampled) coupled with generally low Asian crime rates made it impossible to obtain reliable assessments of Asian group-characteristic violent crime rates, or even if they have one.
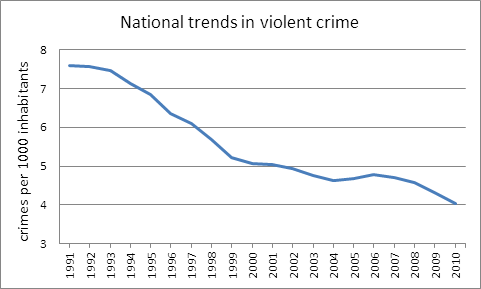
It has been conjectured that the contribution of Hispanics to violent crime is on the point of advancing to the standing enjoyed by blacks. This, however, is not confirmed by our evidence, at least in our largest cities. Whoever thinks or has thought this to be so has come to this determination from evidence not directly related to what is happening on the street, but rather from incarceration records, court appearances or sentencing data. When crimes rather than criminals are counted, and the Hispanic effect is appropriately removed, the data show that violent crime rates for Hispanics and non-Hispanic whites, though a bit higher for Hispanics, are in actual fact quite similar. As for blacks, their crime rate remains by any measure uniquely high. Crime rates are not static. They change from year to year often trending up or down over time. Figure 3 shows how a crime-reducing zeitgeist swept the nation between 1991 and 2010. But, we ask, in such a rate-reducing climate does the zeitgeist sweep across all groups with equal effect? The model of group-characteristic violent crime rates enables us to answer. And, the answer is a categorical “no.”
In 2010, the national violent crime rate dropped by 6.6% from the previous year. Our big-city sample led the way with a rate drop of 7.9%. The nearly 8% drop in violent crime, however, was almost entirely due to a drop in black crime. The Hispanic and non-Hispanic white rates remained virtually unchanged (see Figure 4). When seeking explanations of crime trends it is helpful to look at the details. The model of group-characteristic crime rates provides the means.
Now my friends I am done. I have laid a trifle of wisdom here for your pleasure and, it is hoped, edification. I thank the FBI and Bureau of the Census for supplying the data without which we could not have defeated the Hispanic effect. Finally, thank you UNZ delegates for allowing me the pleasure of introducing these few ideas to your honored membership, and for the courtesy with which you have heard them.
APPENDIX: Observed and predicted crime rates.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||